告别付费Token!手把手教你在 Windows 本地满血运行 Qwen3.5-9B(LM Studio 篇)
一、引言:为什么要本地跑小模型?
随着 Qwen 3.5 (通义千问) 系列和谷歌 Gemma 等强悍小模型的开源,本地部署大模型的“黄金时代”正式到来。本期我们将实测如何使用 LM Studio V0.4.9,在个人电脑上流畅运行 Qwen 3.5-9B 稠密模型及 Gemma-4-26-a4b MoE 模型。
本地搭建的三大核心优势:
- 💰 零成本:彻底告别昂贵的 API 计费,一次硬件投入,永久免费调用。
- 🔒 保隐私:敏感数据完全本地处理,无需上传云端,杜绝泄露风险。
- ⚡ 极速响应:无视网络波动与 API 额度限流,享受“零延迟”的推断体验。
二、硬件准备:你的电脑能跑吗?
本次演示基于高性能 PC 环境,旨在展示模型的“满血”状态:
- 系统:Windows 11
- 显卡:NVIDIA RTX 5070 Ti (16GB VRAM)
- 处理器:Intel® Core™ Ultra 7 265KF
- 内存:48GB DDR5
三、手把手安装指南:为什么选择 LM Studio?
LM Studio 是目前本地玩转 LLM 的首选工具,原因很简单:
- 界面直观:无需复杂命令行,点击即运行。
- 生态强大:完美支持 HuggingFace 上的 GGUF 格式。
- 跨平台:适配 Windows、macOS (Apple Silicon) 及 Linux。
1. 下载与初始化
- 访问 LM Studio 官网,选择 Windows x64 版本下载。
- 安装过程简单,双击运行即可完成初始化。
- 界面速览:左侧为模型功能Tab,中间为工作区,右侧为参数调优窗口。
四、核心步骤:寻找并加载模型
1. 搜索 Qwen 3.5
在搜索框输入关键词 Qwen 3.5-9B 和 Gemma-4-26-a4b 。推荐选择 Qwen 官方 或 LM Studio Community 提供的 GGUF 版本。
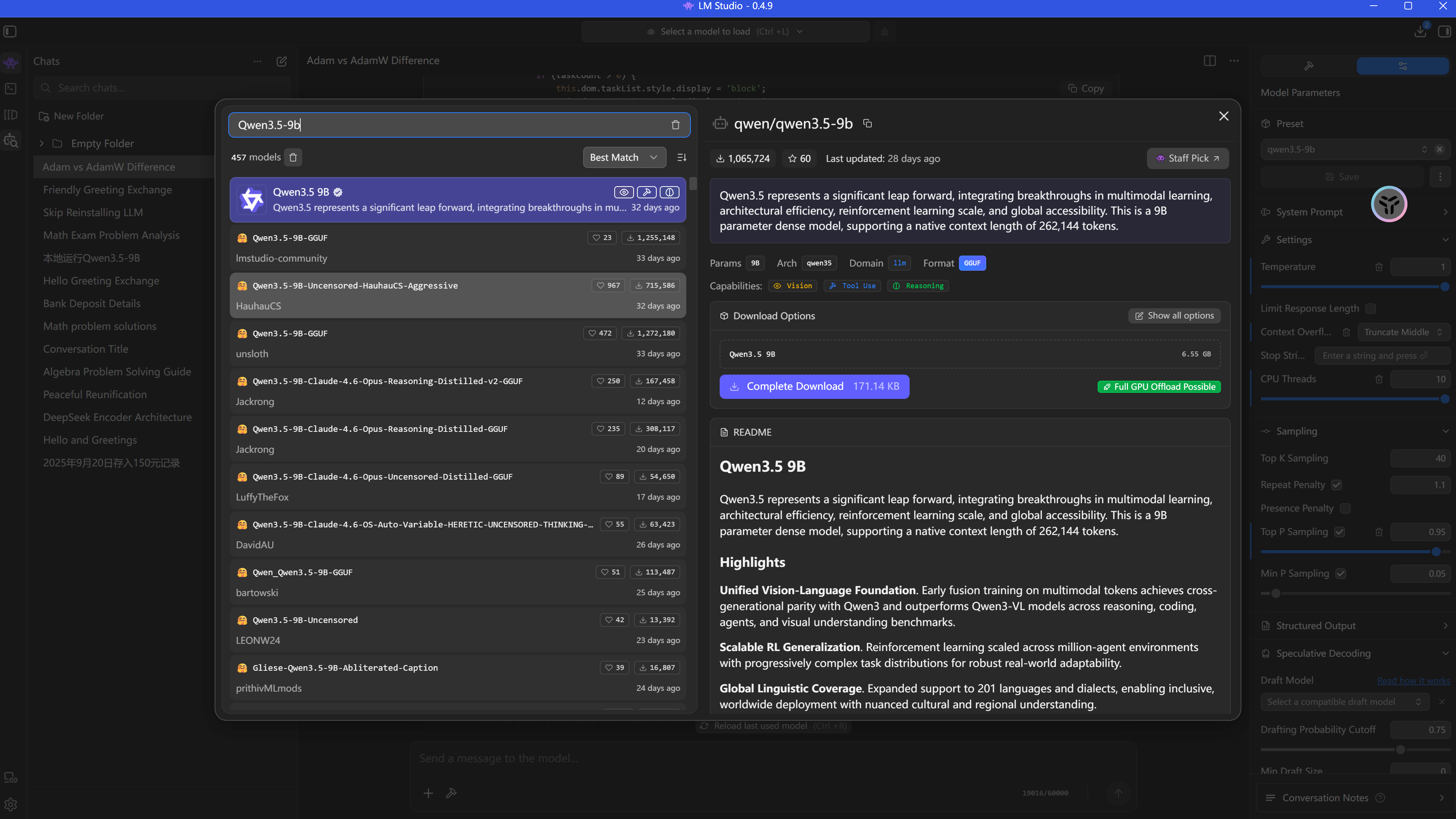 选中,在右边的框中断句
选中,在右边的框中断句download
2. 量化选择策略(关键点)
量化是在精度与资源间找平衡。在 MK 模式下观察显存占用:
- Q4_K_M (推荐):精度与体积的最佳平衡点,9B 模型显存占用约 6GB-8GB。
- Q8_0:接近原生态精度,但显存需求翻倍。
- 决策逻辑:如果显存为 16GB,建议首选 Q4_K_M 以留出更多空间给上下文缓存。
五、深度调优:如何达到“满血”状态?
下载完成后,选择模型进行模型加载,要在本地压榨出模型的全部性能,请按照以下参数配置:
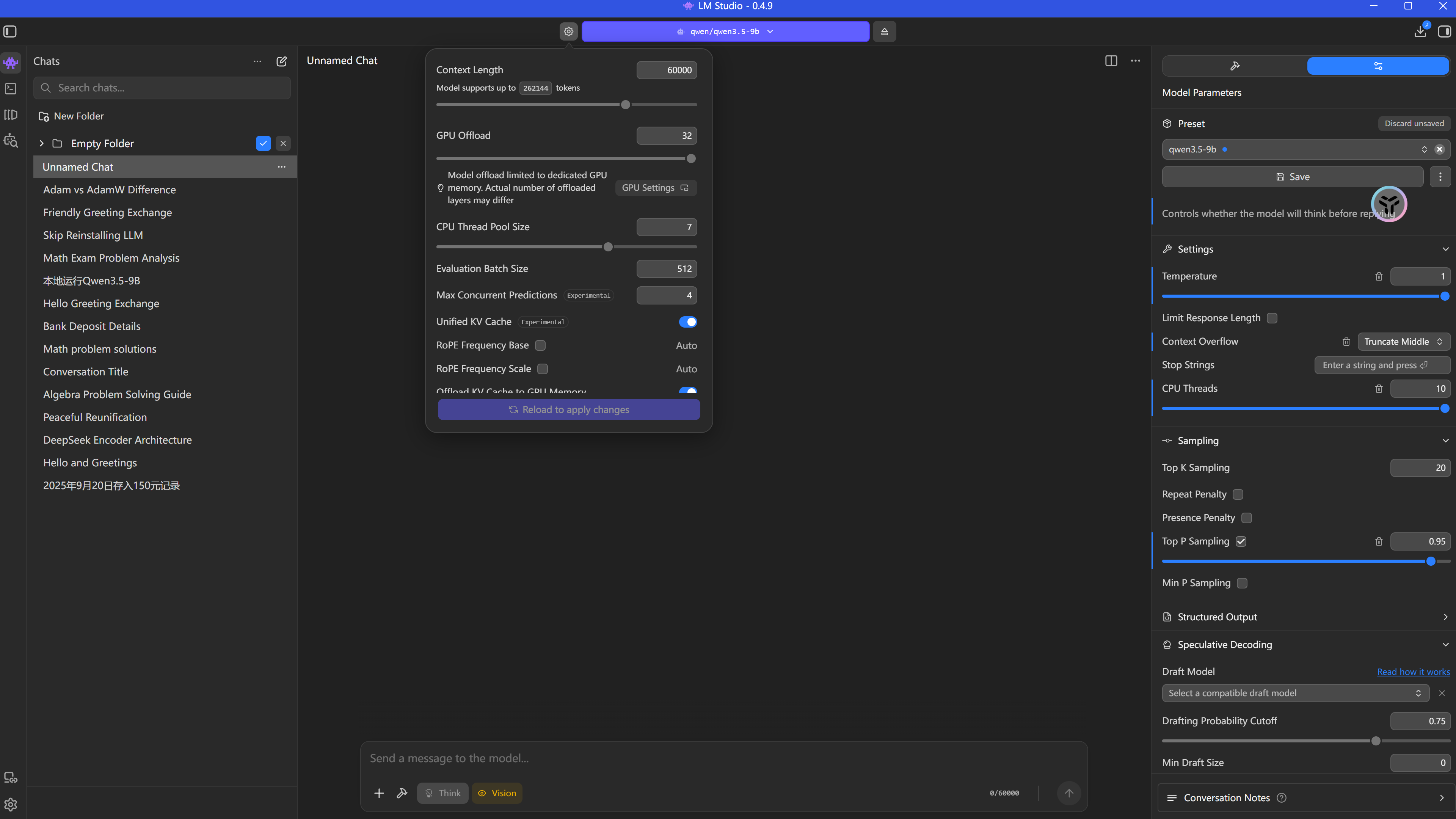
1. GPU Offload (显存卸载)
- 设置建议:16GB 显存环境下,建议将
GPU Offload设置为 Max (全部层数)。 - 原理:让 GPU 承担 100% 的计算量,避免 CPU 拖后腿,极大提升生成速度。
2. Flash Attention (闪电注意力机制)
- 状态:务必开启 (True)。
- 效果:在不损失精度的前提下,推理速度提升 2-3 倍,显存占用大幅降低,是处理长文本的“神技”。
3. Context Window (上下文窗口)
- Qwen 3.5 支持超长上下文。建议根据内存情况设置在 8k - 32k 之间,处理长文档不再断片。
4. K/V Cache 量化
- 为了进一步节省显存,K/V Cache 可以选择 Q8_0 或 Q4_0。这就像是用不同精度的尺子测量中间数据,Q4_K_M 依然是性价比最高的全能选型。
六、全方位能力测试
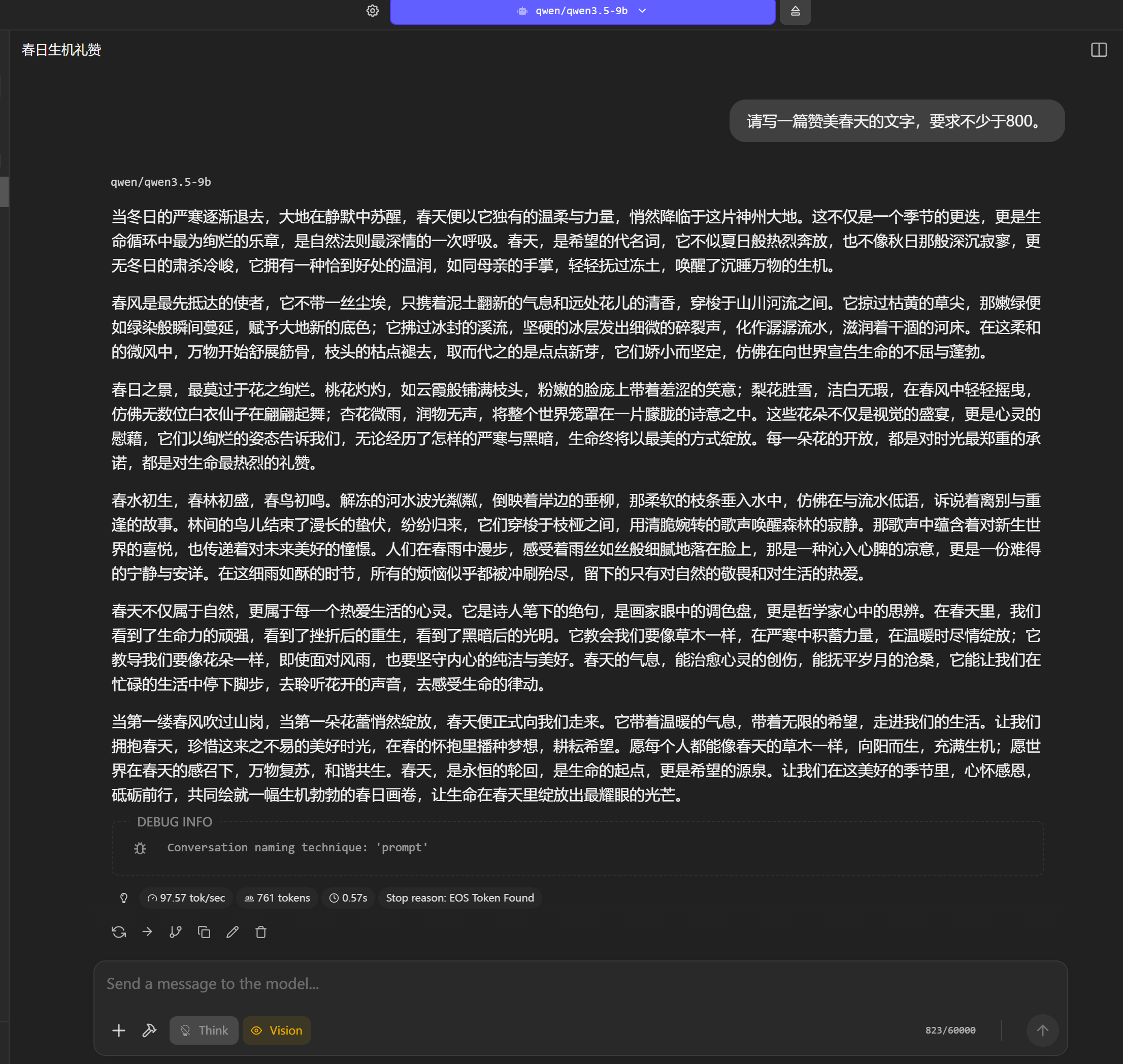
- 文学创作:输入“赞美春天的文字(800字以上)”,考察模型语言组织的连贯性。

- 代码实战:测试 HTML/JS 实现“带优先级标记的 Todo App”,验证逻辑严密性。
- 逻辑数学:实测初中数学竞赛题,观察模型在复杂推理下的正确率。

七、FAQ:常见故障排查
- Q:遇到显存溢出 (OOM) 怎么办?
- A:降低量化等级(如从 Q8 降到 Q4),或减少
GPU Offload层数。
- A:降低量化等级(如从 Q8 降到 Q4),或减少
- Q:回复速度慢(Token 蹦得慢)?
- A:检查显卡驱动是否更新,确认
Flash Attention已开启,并缩短Context Window。
- A:检查显卡驱动是否更新,确认
八、进阶玩法:解锁本地 AI 更多可能
- JS 代码执行:利用模型生成并运行计算代码(如斐波那契数列)。
- 本地 RAG:挂载 PDF 或 Markdown 知识库,训练一个只属于你的私人 AI 助手。
- lm studio Developer 模式 通过设置developer 模式,可以提供API 调用
- claude Code 接入 lm studio 的local Server
- openclaw 龙虾本地接入 lm studio 的local Server
告别付费Token!手把手教你在 Windows 本地满血运行 Qwen3.5-9B(LM Studio 篇)
https://join2017.github.io/2026/04/02/告别付费 Token!手把手教你在 Windows 本地满血运行 Qwen3.5-9B(LM Studio 篇)/